
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Oracel
- R
- 데이터 분석
- 튜닝
- sklearn
- 머신러닝
- 파이썬
- matplotlib
- 실기
- SQL
- python3
- 실습
- 카카오
- Kaggle
- 알고리즘
- 코딩테스트
- seaborn
- level 2
- Numpy
- Python
- pandas
- oracle
- level 1
- 빅분기
- 빅데이터 분석 기사
- 오라클
- 프로그래머스
Archives
- Today
- Total
라일락 꽃이 피는 날
[빅분기 실기] 투표기반 앙상블 (Voting Ensemble) 본문
728x90
투표기반 앙상블 (Voting Ensemble)
여러 분류기를 학습시킨 후 각각의 분류기가 예측하는 레이블 범주가 가장 많이 나오는 범주를 예측하는 방법
옵션으로 범주 기반일 경우 Hard Learner, 확률 기반일 경우 Soft Learner 를 선택한다.
범주 기반은 1, 2와 같이 결과가 범주로 많이 나타난 것을 선택하는 방법이고,
확률 기반은 예측 확률의 평균으로 0.5 이상인지 아닌지에 따라 범주를 선택하는 것이다.
[주요 하이퍼파라미터]
<분류>
- voting : hard(범주), soft(확률)
Part 1. 분류 (Classification)
1. 분석 데이터 준비
import pandas as pd
# 유방암 예측 분류 데이터
data1=pd.read_csv('breast-cancer-wisconsin.csv', encoding='utf-8')
X=data1[data1.columns[1:10]]
y=data1[["Class"]]
1-2. train-test 데이터셋 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(X, y, stratify=y, random_state=42)
1-3. Min-Max 정규화
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
scaler.fit(X_train)
X_scaled_train=scaler.transform(X_train)
X_scaled_test=scaler.transform(X_test)
2. 모델 적용
2-1. 강한 학습기 (Hard Learner)
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
logit_model= LogisticRegression(random_state=42)
rnf_model = RandomForestClassifier(random_state=42)
svm_model = SVC(random_state=42)
voting_hard = VotingClassifier(
estimators=[('lr', logit_model), ('rf', rnf_model), ('svc', svm_model)], voting='hard')
voting_hard.fit(X_scaled_train, y_train)
from sklearn.metrics import accuracy_score
for clf in (logit_model, rnf_model, svm_model, voting_hard):
clf.fit(X_scaled_train, y_train)
y_pred = clf.predict(X_scaled_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))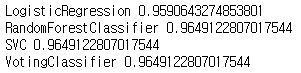
① 로지스틱 회귀모델
from sklearn.metrics import confusion_matrix
log_pred_train=logit_model.predict(X_scaled_train)
log_confusion_train=confusion_matrix(y_train, log_pred_train)
print("로지스틱 분류기 훈련데이터 오차행렬:\n", log_confusion_train)
log_pred_test=logit_model.predict(X_scaled_test)
log_confusion_test=confusion_matrix(y_test, log_pred_test)
print("로지스틱 분류기 테스트데이터 오차행렬:\n", log_confusion_test)
② 서포트 벡터 머신
svm_pred_train=svm_model.predict(X_scaled_train)
svm_confusion_train=confusion_matrix(y_train, svm_pred_train)
print("서포트벡터머신 분류기 훈련데이터 오차행렬:\n", svm_confusion_train)
svm_pred_test=svm_model.predict(X_scaled_test)
svm_confusion_test=confusion_matrix(y_test, svm_pred_test)
print("서포트벡터머신 분류기 훈련데이터 오차행렬:\n", svm_confusion_test)
③ 랜덤 포레스트
rnd_pred_train=rnf_model.predict(X_scaled_train)
rnd_confusion_train=confusion_matrix(y_train, rnd_pred_train)
print("랜덤포레스트 분류기 훈련데이터 오차행렬:\n", rnd_confusion_train)
rnd_pred_test=rnf_model.predict(X_scaled_test)
rnd_confusion_test=confusion_matrix(y_test, rnd_pred_test)
print("랜덤포레스트 분류기 테스트데이터 오차행렬:\n", rnd_confusion_test)
④ 투표기반 앙상블
voting_pred_train=voting_hard.predict(X_scaled_train)
voting_confusion_train=confusion_matrix(y_train, voting_pred_train)
print("투표분류기 분류기 훈련데이터 오차행렬:\n", voting_confusion_train)
voting_pred_test=voting_hard.predict(X_scaled_test)
voting_confusion_test=confusion_matrix(y_test, voting_pred_test)
print("투표분류기 분류기 훈련데이터 오차행렬:\n", voting_confusion_test)
2-2. 약한 학습기 (Soft Learner)
logit_model = LogisticRegression(random_state=42)
rnf_model = RandomForestClassifier(random_state=42)
svm_model = SVC(probability=True, random_state=42)
voting_soft = VotingClassifier(
estimators=[('lr', logit_model), ('rf', rnf_model), ('svc', svm_model)], voting='soft')
voting_soft.fit(X_scaled_train, y_train)
from sklearn.metrics import accuracy_score
for clf in (logit_model, rnf_model, svm_model, voting_soft):
clf.fit(X_scaled_train, y_train)
y_pred = clf.predict(X_scaled_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))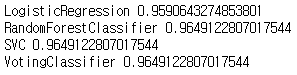
① 투표기반 앙상블
voting_pred_train=voting_soft.predict(X_scaled_train)
voting_confusion_train=confusion_matrix(y_train, voting_pred_train)
print("투표분류기 분류기 훈련데이터 오차행렬:\n", voting_confusion_train)
voting_pred_test=voting_soft.predict(X_scaled_test)
voting_confusion_test=confusion_matrix(y_test, voting_pred_test)
print("투표분류기 분류기 훈련데이터 오차행렬:\n", voting_confusion_test)
Part 2. 회귀 (Regression)
1. 분석 데이터 준비
# 주택 가격 데이터
data2=pd.read_csv('house_price.csv', encoding='utf-8')
X=data2[data2.columns[1:5]]
y=data2[["house_value"]]
1-2. train-test 데이터셋 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(X, y, random_state=42)
1-3. Min-Max 정규화
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
scaler.fit(X_train)
X_scaled_train=scaler.transform(X_train)
X_scaled_test=scaler.transform(X_test)
2. 모델 적용
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import VotingRegressor
linear_model= LinearRegression()
rnf_model = RandomForestRegressor(random_state=42)
voting_regressor = VotingRegressor(estimators=[('lr', linear_model), ('rf', rnf_model)])
voting_regressor.fit(X_scaled_train, y_train)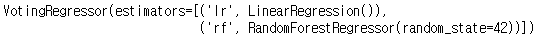
2-1. 훈련 데이터
pred_train=voting_regressor.predict(X_scaled_train)
voting_regressor.score(X_scaled_train, y_train) # 0.7962532705428835
2-2. 테스트 데이터
pred_test=voting_regressor.predict(X_scaled_test)
voting_regressor.score(X_scaled_test, y_test) # 0.5936371957936408
① RMSE (Root Mean Squared Error)
import numpy as np
from sklearn.metrics import mean_squared_error
MSE_train = mean_squared_error(y_train, pred_train)
MSE_test = mean_squared_error(y_test, pred_test)
print("훈련 데이터 RMSE:", np.sqrt(MSE_train))
print("테스트 데이터 RMSE:", np.sqrt(MSE_test))
728x90
'데이터 분석 > 빅데이터 분석 기사' 카테고리의 다른 글
| [빅분기 실기] 앙상블 부스팅 (Boosting) (0) | 2022.06.19 |
|---|---|
| [빅분기 실기] 앙상블 배깅 (Bagging) (0) | 2022.06.19 |
| [빅분기 실기] 랜덤 포레스트 (Random Forest) (0) | 2022.06.18 |
| [빅분기 실기] 의사결정나무 (Decision Tree) (0) | 2022.06.18 |
| [빅분기 실기] 서포트 벡터머신 (SVM) (0) | 2022.06.18 |