
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- matplotlib
- R
- 실기
- level 1
- Kaggle
- 카카오
- SQL
- Numpy
- 코딩테스트
- 튜닝
- python3
- 빅데이터 분석 기사
- pandas
- 머신러닝
- 알고리즘
- seaborn
- 파이썬
- 오라클
- level 2
- 데이터 분석
- oracle
- 프로그래머스
- Oracel
- 실습
- Python
- 빅분기
- sklearn
- Today
- Total
라일락 꽃이 피는 날
[Sklearn] 분류 (classification) 본문
1. Logistic Regression
로지스틱 회귀는 독립 변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는데 사용되는 통계 기법이다.
서포트 벡터 머신(SVM)과 같은 알고리즘은 이진 분류만 가능하다. (2개의 클래스 판별만 가능)
3개 이상의 클래스에 대한 판별을 진행하는 경우, 다음과 같은 전략으로 판별한다.
① one-vs-rest(OvR)
K개의 클래스가 존재할 때 1개의 클래스를 제외한 다른 클래스를 K개 만들어, 각각의 이진 분류에 대한 확률을 구하고 총합을 통해 최종 클래스를 판별한다.
② one-vs-one(OvO)
4개의 계절을 구분하는 클래스가 존재한다고 가정했을 때, 0vs1, 0vs2, 0vs3, ... , 2vs3 까지 NX(N-1)/2개의 분류기를 만들어 가장 많이 양성으로 선택된 클래스를 판별한다.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(x_train, y_train)
prediction = model.predict(x_valid)
(prediction == y_valid).mean() # 평가
2. SGDClassifier
stochastic gradient descent(SGD): 확률적 경사 하강법
from sklearn.linear_model import SGDClassifier
sgd = SGDClassifier()
sgd.fit(x_train, y_train)
prediction = sgd.predict(x_valid)
(prediction == y_valid).mean()
3. 하이퍼 파라미터(hyper-parameter) 튜닝
알고리즘별 hyper-parameter의 종류가 다양하다.
모두 다 외워서 할 수는 없으니, 문서를 보고 적절한 가설을 세운 다음 적용하면서 검증한다.
random_state: 하이퍼 파라미터 튜닝시, 고정할 것
n_jobs=-1: CPU를 모두 사용 (학습 속도가 빠름)
from sklearn.linear_model import SGDClassifier
sgd = SGDClassifier(penalty='elasticnet', random_state=0, n_jobs=-1)
sgd.fit(x_train, y_train)
prediction = sgd.predict(x_valid)
(prediction == y_valid).mean()
4. KNeighborsClassifier 최근접 이웃 알고리즘

from sklearn.neighbors import KNeighborsClassifier
knc = KNeighborsClassifier()
knc.fit(x_train, y_train)
knc_pred = knc.predict(x_valid)
(knc_pred == y_valid).mean()
일반적으로 n_neighbors는 홀수를 넣는다. 짝수를 넣으면 동점확률이 생길 수 있기 때문이다.
knc = KNeighborsClassifier(n_neighbors=9)
knc.fit(x_train, y_train)
knc_pred = knc.predict(x_valid)
(knc_pred == y_valid).mean()
5. 서포트 벡터 머신 (SVC)
새로운 데이터가 어느 카테고리에 속할지 판단하는 비확률적 이진 선형 분류 모델을 만든다.
경계로 표현되는 데이터 중 가장 큰 폭을 가진 경계를 찾는 알고리즘이다.
LogisticRegression과 같이 이진 분류만 가능하다. (2개의 클래스 판별만 가능)
3개 이상의 클래스에 대한 판별을 진행하는 경우, OvsR 전략을 사용한다.

from sklearn.svm import SVC
svc = SVC()
svc.fit(x_train, y_train)
svc_pred = svc.predict(x_valid)
(svc_pred == y_valid).mean()

decision_function(): 각 클래스별 확률값 return

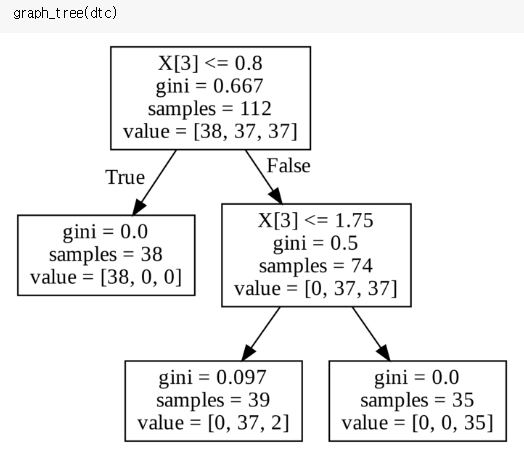
6. 의사 결정 나무 (Decision Tree)
스무고개처럼 나무 가지치기를 통해 소그룹으로 나누어 판별하는 방법이다.
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier(random_state=0)
dtc.fit(x_train, y_train)
dtc_pred = dtc.predict(x_valid)
(dtc_pred == y_valid).mean()
from sklearn.tree import export_graphviz
from subprocess import call
def graph_tree(model):
# .dot 파일로 export
export_graphviz(model, out_file='tree.dot')
# 생성된 .dot 파일을 .png로 변환
call(['dot', '-Tpng', 'tree.dot', '-o', 'decistion-tree.png', '-Gdpi=600'])
# .png 출력
return Image(filename = 'decistion-tree.png', width=500)
gini 계수: 불순도를 의미하며, 계수가 높을수록 엔트로피가 크다는 의미
엔트로피가 크다는 의미는 클래스가 혼잡하게 섞여 있다는 뜻
dtc = DecisionTreeClassifier(max_depth=2)
dtc.fit(x_train, y_train)
dtc_pred = dtc.predict(x_valid)
'데이터 분석 > Python' 카테고리의 다른 글
| [Sklearn] MSE, MAE, RMSE (0) | 2021.05.13 |
|---|---|
| [Sklearn] 오차 (Error) (0) | 2021.05.13 |
| [Sklearn] 데이터 셋 (dataset) (0) | 2021.05.13 |
| [Sklearn] 전처리 (pre-processing) (0) | 2021.05.11 |
| [Sklearn] Training Set, Test Set (0) | 2021.05.11 |