데이터 분석/Python
회귀분석
eunki
2021. 5. 27. 13:17
728x90
1. 데이터 전처리
1) 데이터 타입 변경
df['Legendary'] = df['Legendary'].astype(int)
df['Generation'] = df['Generation'].astype(str)
preprocessed_df = df[['Type 1', 'Type 2', 'Total', 'HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed', 'Generation', 'Legendary']]
preprocessed_df.head()
2) one-hot encoding
def make_list(x1, x2):
type_list = []
type_list.append(x1)
if x2 is not np.nan:
type_list.append(x2)
return type_list
preprocessed_df['Type'] = preprocessed_df.apply(lambda x: make_list(x['Type 1'], x['Type 2']), axis=1)
preprocessed_df.head()
del preprocessed_df['Type 1']
del preprocessed_df['Type 2']
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer()
preprocessed_df= preprocessed_df.join(pd.DataFrame(mlb.fit_transform(preprocessed_df.pop('Type')), columns=mlb.classes_))
preprocessed_df.head()
encoded_df = pd.get_dummies(preprocessed_df)
encoded_df.head()
3) 피처 표준화
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scale_columns = ['Total', 'HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed']
preprocessed_df[scale_columns] = scaler.fit_transform(preprocessed_df[scale_columns])
preprocessed_df.head()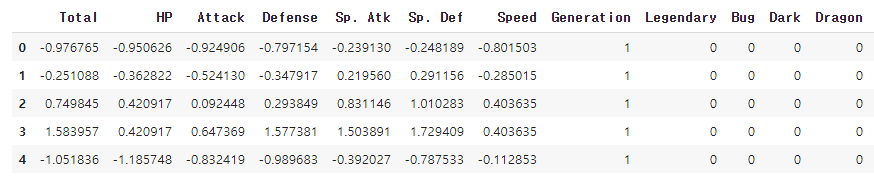
4) 데이터셋 분리
from sklearn.model_selection import train_test_split
x = preprocessed_df.loc[:, preprocessed_df.columns != 'Legendary']
y = preprocessed_df['Legendary']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=33)
x_train.shape # (600, 26)
x_test.shape # (200, 26)
2. 회귀 분석 모델 학습
1) 모델 학습
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(random_state=0)
lr.fit(x_train, y_train)
y_pred = lr.predict(x_test)
2) 모델 평가
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
accuracy_score(y_test, y_pred) # 0.955
precision_score(y_test, y_pred) # 0.6153846153846154
recall_score(y_test, y_pred) # 0.6666666666666666
f1_score(y_test, y_pred) # 0.64from sklearn.metrics import confusion_matrix
confmat = confusion_matrix(y_true=y_test, y_pred=y_pred)
confmat # [[183 5]
# [ 4 8]]
3. 클래스 불균형 조정
1) 1:1 샘플링
positive_random_idx= preprocessed_df[preprocessed_df['Legendary']==1].sample(65, random_state=33).index.tolist()
negative_random_idx= preprocessed_df[preprocessed_df['Legendary']==0].sample(65, random_state=33).index.tolist()
2) 데이터셋 분리
random_idx = positive_random_idx + negative_random_idx
x = preprocessed_df.loc[random_idx, preprocessed_df.columns != 'Legendary']
y = preprocessed_df['Legendary'][random_idx]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=33)
x_train.shape # (97, 26)
x_test.shape # (33, 26)
3) 모델 재학습
lr = LogisticRegression(random_state=0)
lr.fit(x_train, y_train)
y_pred = lr.predict(x_test)
4) 모델 재평가
accuracy_score(y_test, y_pred) # 0.9090909090909091
precision_score(y_test, y_pred) # 0.8461538461538461
recall_score(y_test, y_pred) # 0.9166666666666666
f1_score(y_test, y_pred) # 0.8799999999999999confmat = confusion_matrix(y_true=y_test, y_pred=y_pred)
confmat # [[19 2]
# [ 1 11]]
4. 학습 결과 해석
1) R2 score, RMSE score 계산
model.score(x_train, y_train) # 0.7490284664199387
model.score(x_test, y_test) # 0.700934213532155from sklearn.metrics import mean_squared_error
from math import sqrt
y_predictions = lr.predict(x_train)
sqrt(mean_squared_error(y_train, y_predictions)) # 4.672162734008587
y_predictions = lr.predict(x_test)
sqrt(mean_squared_error(y_test, y_predictions)) # 4.61495178491331
2) 피처 유의성 검정 (stats model)
import statsmodels.api as sm
x_train = sm.add_constant(x_train)
model = sm.OLS(y_train, x_train).fit()
model.summary()
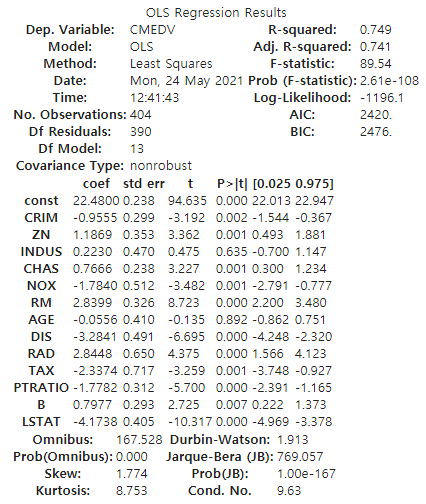
- R-Square 0.749로 높은 편이다.
- P-value 0.05수준에서 유의한 변수는 CRIM, ZN, CHAS, NOX, RM, DIS, RAD, TAX, PTRATIO, B, LSTAT 이다.
- INDUS, AGE는 유의하지 않는 것으로 나타났다. 즉, INDUS, AGE가 CMEDV에 미치는 영향은 유의하지 않다고 할 수 있다.
- 회귀식: CMEDV = 22.4800 - 0.9555*CRIM + 1.1869*ZN + ... + 0.7977*B - 4.1738*LSTAT
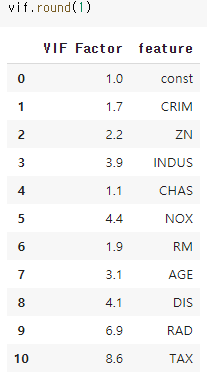
3) 다중 공선성
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(x_train.values, i) for i in range(x_train.shape[1])]
vif["feature"] = x_train.columns
728x90