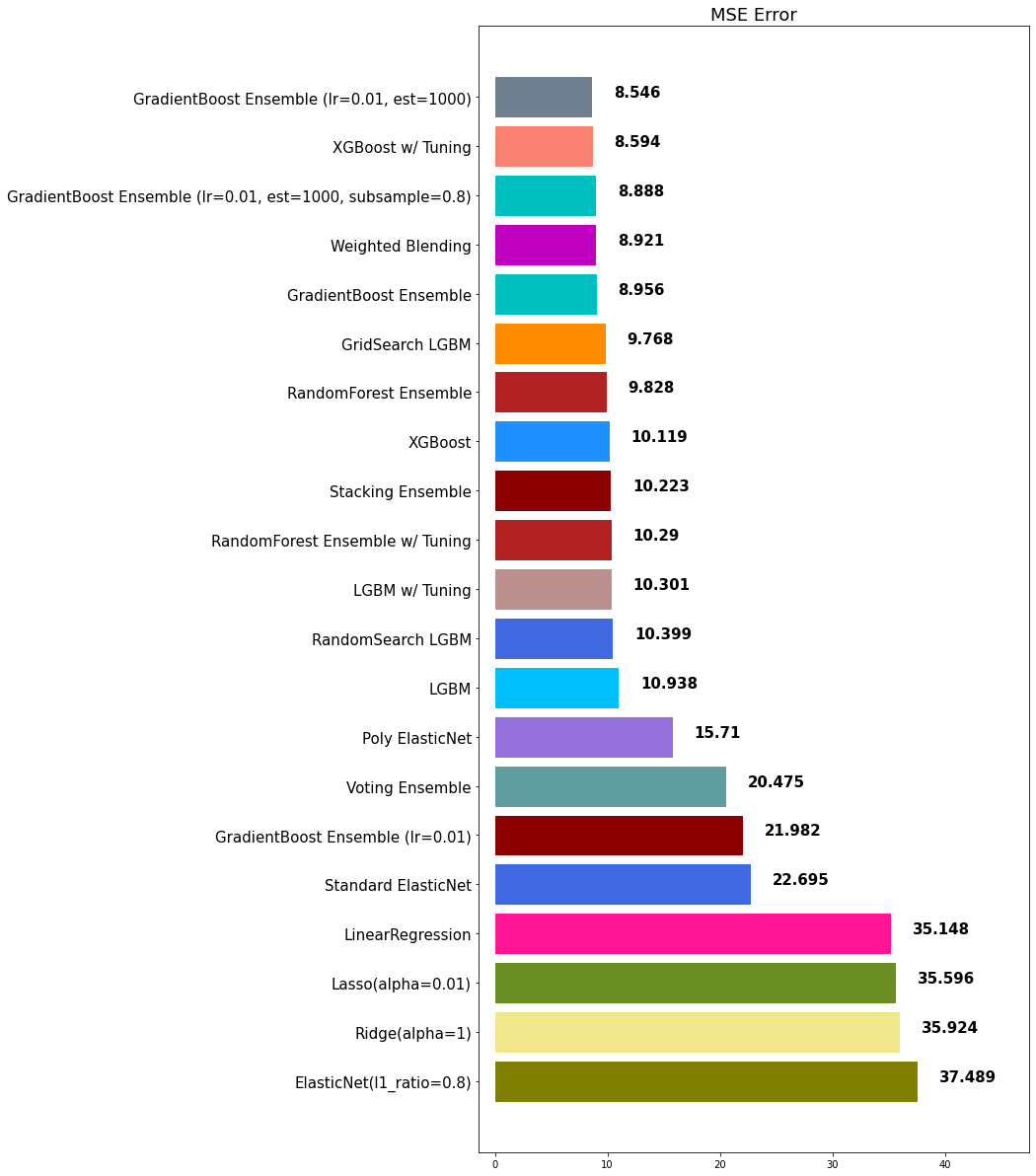
[Sklearn] Hyperparameter 튜닝
Hyperparameter 튜닝
hypterparameter 튜닝시 경우의 수가 너무 많기 때문에 자동화할 필요가 있다.
자주 사용되는 hyperparameter 튜닝을 돕는 클래스는 다음 2가지가 있다.
- RandomizedSearchCV
- GridSearchCV
적용하는 방법
1. 사용할 Search 방법을 선택한다.
2. hyperparameter 도메인을 설정한다. (max_depth, n_estimators 등)
3. 학습을 시킨 후, 기다린다.
4. 도출된 결과 값을 모델에 적용하고 성능을 비교한다.
RandomizedSearchCV
모든 매개 변수 값이 시도되는 것이 아니라 지정된 분포에서 고정 된 수의 매개 변수 설정이 샘플링된다.
시도 된 매개 변수 설정의 수는 n_iter에 의해 제공된다.
주요 Hyperparameter (LGBM)
- random_state: 랜덤 시드 고정 값. 고정해두고 튜닝할 것!
- n_jobs: CPU 사용 갯수
- learning_rate: 학습율. 너무 큰 학습율은 성능을 떨어뜨리고, 너무 작은 학습율은 학습이 느리다. 적절한 값을 찾아야함. n_estimators와 같이 튜닝 (default=0.1)
- n_estimators: 부스팅 스테이지 수. (랜덤포레스트 트리의 갯수 설정과 비슷한 개념) (default=100)
- max_depth: 트리의 깊이. 과대적합 방지용 (default=3)
- colsample_bytree: 샘플 사용 비율 (max_features와 비슷한 개념). 과대적합 방지용 (default=1.0)
from sklearn.model_selection import RandomizedSearchCV
params = {
'n_estimators': [200, 500, 1000, 2000],
'learning_rate': [0.1, 0.05, 0.01],
'max_depth': [6, 7, 8],
'colsample_bytree': [0.8, 0.9, 1.0],
'subsample': [0.8, 0.9, 1.0]
}
clf = RandomizedSearchCV(LGBMRegressor(), params, random_state=42, cv=3, n_iter=25, scoring='neg_mean_squared_error')
clf.fit(x_train, y_train)
best_score_

best_params_

best_params_ 결과를 Hyperparameter에 적용하기
lgbm_best = LGBMRegressor(n_estimators=2000, subsample=0.8, max_depth=7, learning_rate=0.01, colsample_bytree=0.8)
lgbm_best_pred = lgbm_best.fit(x_train, y_train).predict(x_test)

GridSearchCV
모든 매개 변수 값에 대하여 완전 탐색을 시도한다.
따라서, 최적화할 parameter가 많다면 시간이 매우 오래걸린다.
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators': [500, 1000],
'learning_rate': [0.1, 0.05, 0.01],
'max_depth': [7, 8],
'colsample_bytree': [0.8, 0.9],
'subsample': [0.8, 0.9,],
}
grid_search = GridSearchCV(LGBMRegressor(), params, cv=3, n_jobs=-1, scoring='neg_mean_squared_error')
grid_search.fit(x_train, y_train)
best_score_
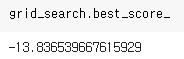
best_params_

best_params_ 결과를 Hyperparameter에 적용하기
lgbm_best = LGBMRegressor(n_estimators=500, subsample=0.8, max_depth=7, learning_rate=0.05, colsample_bytree=0.8)
lgbm_best_pred = lgbm_best.fit(x_train, y_train).predict(x_test)