데이터 분석/Python
[Sklearn] 규제 (Regularization)
eunki
2021. 5. 13. 23:47
728x90
규제 (Regularization)
학습이 과대적합 되는 것을 방지하고자 일종의 penalty를 부여하는 것
L2 규제 (L2 Regularization) - 릿지(Ridge)

- 각 가중치 제곱의 합에 규제 강도(Regularization Strength) λ를 곱한다.
- λ를 크게 하면 가중치가 더 많이 감소되고(규제를 중요시함), λ를 작게 하면 가중치가 증가한다(규제를 중요시하지 않음).
L1 규제 (L1 Regularization) - 라쏘(Lasso)
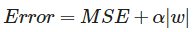
- 가중치의 제곱의 합이 아닌 가중치의 합을 더한 값에 규제 강도(Regularization Strength) λ를 곱하여 오차에 더한다.
- 어떤 가중치(w)는 실제로 0이 된다. 즉, 모델에서 완전히 제외되는 특성이 생기는 것이다.
→ L2 규제가 L1 규제에 비해 더 안정적이라 일반적으로는 L2규제가 더 많이 사용된다.
릿지(Ridge)
from sklearn.linear_model import Ridge
alphas = [100, 10, 1, 0.1, 0.01, 0.001, 0.0001] # 값이 커질 수록 큰 규제
for alpha in alphas:
ridge = Ridge(alpha=alpha)
ridge.fit(x_train, y_train)
pred = ridge.predict(x_test)
coef_ 속성

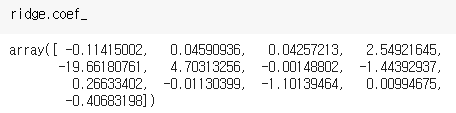
ridge_100 = Ridge(alpha=100)
ridge_100.fit(x_train, y_train)
ridge_pred_100 = ridge_100.predict(x_test)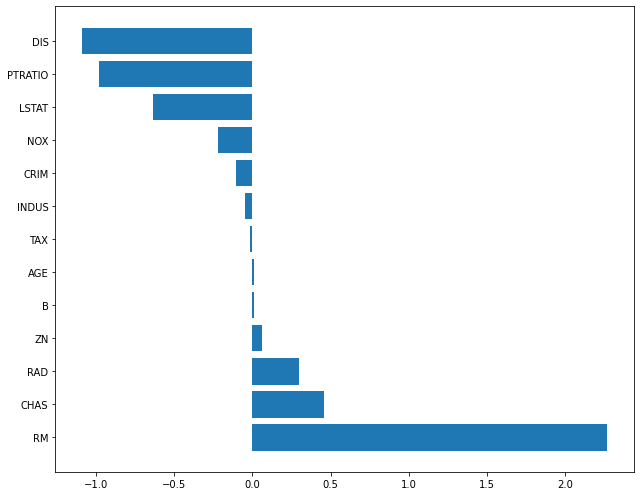
ridge_001 = Ridge(alpha=0.001)
ridge_001.fit(x_train, y_train)
ridge_pred_001 = ridge_001.predict(x_test)
라쏘(Lasso)
from sklearn.linear_model import Lasso
alphas = [100, 10, 1, 0.1, 0.01, 0.001, 0.0001]
for alpha in alphas:
lasso = Lasso(alpha=alpha)
lasso.fit(x_train, y_train)
pred = lasso.predict(x_test)

coef_ 속성
lasso_100 = Lasso(alpha=100)
lasso_100.fit(x_train, y_train)
lasso_pred_100 = lasso_100.predict(x_test)


lasso_001 = Lasso(alpha=0.001)
lasso_001.fit(x_train, y_train)
lasso_pred_001 = lasso_001.predict(x_test)


728x90