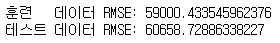[빅분기 실기] 앙상블 부스팅 (Boosting)
앙상블 배깅 (Boosting)
여러 개의 약한 학습기를 순차적으로 학습시켜 예측하면서
잘 못 예측한 데이터에 가중치를 부여하여 오류를 개선해 나가며 학습하는 앙상블 모델
배깅이 병렬식 앙상블인 반면, 부스팅은 순차적인 직렬식 앙상블이다.
[주요 하이퍼파라미터]
1. AdaBoosting
- base_estimator
- n_estimator : 모델 수행횟수
2. GradientBoosting
- learning_rate : 학습률
Part 1. 분류 (Classification)
1. 분석 데이터 준비
import pandas as pd
# 암 예측 분류 데이터
data=pd.read_csv('breast-cancer-wisconsin.csv', encoding='utf-8')
X=data[data.columns[1:10]]
y=data[["Class"]]
1-2. train-test 데이터셋 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(X, y, stratify=y, random_state=42)
1-3. Min-Max 정규화
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
scaler.fit(X_train)
X_scaled_train=scaler.transform(X_train)
X_scaled_test=scaler.transform(X_test)
2. AdaBoosting
2-1. 훈련 데이터
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100, random_state=0)
model.fit(X_scaled_train, y_train)
pred_train=model.predict(X_scaled_train)
model.score(X_scaled_train, y_train) # 1.0
① 오차행렬 (confusion matrix)
from sklearn.metrics import confusion_matrix
confusion_train=confusion_matrix(y_train, pred_train)
print("훈련데이터 오차행렬:\n", confusion_train)
정상 333명, 환자 179명을 정확하게 분류했다.
② 분류예측 레포트 (classification report)
from sklearn.metrics import classification_report
cfreport_train=classification_report(y_train, pred_train)
print("분류예측 레포트:\n", cfreport_train)
정밀도(precision) = 1.0, 재현율(recall) = 1.0
2-2. 테스트 데이터
pred_test=model.predict(X_scaled_test)
model.score(X_scaled_test, y_test) # 0.9532163742690059
① 오차행렬 (confusion matrix)
confusion_test=confusion_matrix(y_test, pred_test)
print("테스트데이터 오차행렬:\n", confusion_test)
정상(0) 중 5명이 오분류, 환자(1) 중 3명이 오분류되었다.
② 분류예측 레포트 (classification report)
cfreport_test=classification_report(y_test, pred_test)
print("분류예측 레포트:\n", cfreport_test)
정밀도(precision) = 0.95, 재현율(recall) = 0.95
3. GradientBoosting
3-1. 훈련 데이터
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)
model.fit(X_scaled_train, y_train)
pred_train=model.predict(X_scaled_train)
model.score(X_scaled_train, y_train) # 1.0
① 오차행렬 (confusion matrix)
from sklearn.metrics import confusion_matrix
confusion_train=confusion_matrix(y_train, pred_train)
print("훈련데이터 오차행렬:\n", confusion_train)
정상 333명, 환자 179명을 정확하게 분류했다.
3-2. 테스트 데이터
pred_test=model.predict(X_scaled_test)
model.score(X_scaled_test, y_test) # 0.9649122807017544
① 오차행렬 (confusion matrix)
confusion_test=confusion_matrix(y_test, pred_test)
print("테스트데이터 오차행렬:\n", confusion_test)
정상(0) 중 5명이 오분류, 환자(1) 중 1명이 오분류되었다.
Part 2. 회귀 (Regression)
1. 분석 데이터 준비
# 주택 가격 데이터
data2=pd.read_csv('house_price.csv', encoding='utf-8')
X=data2[data2.columns[1:5]]
y=data2[["house_value"]]
1-2. train-test 데이터셋 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(X, y, random_state=42)
1-3. Min-Max 정규화
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
scaler.fit(X_train)
X_scaled_train=scaler.transform(X_train)
X_scaled_test=scaler.transform(X_test)
2. AdaBoosting
2-1. 훈련 데이터
from sklearn.ensemble import AdaBoostRegressor
model = AdaBoostRegressor(random_state=0, n_estimators=100)
model.fit(X_scaled_train, y_train)
pred_train=model.predict(X_scaled_train)
model.score(X_scaled_train, y_train) # 0.4353130085971758
2-2. 테스트 데이터
pred_test=model.predict(X_scaled_test)
model.score(X_scaled_test, y_test) # 0.43568387094087124
① RMSE (Root Mean Squared Error)
import numpy as np
from sklearn.metrics import mean_squared_error
MSE_train = mean_squared_error(y_train, pred_train)
MSE_test = mean_squared_error(y_test, pred_test)
print("훈련 데이터 RMSE:", np.sqrt(MSE_train))
print("테스트 데이터 RMSE:", np.sqrt(MSE_test))
3. GradientBoosting
3-1. 훈련 데이터
from sklearn.ensemble import GradientBoostingRegressor
model = GradientBoostingRegressor(random_state=0)
model.fit(X_scaled_train, y_train)
pred_train=model.predict(X_scaled_train)
model.score(X_scaled_train, y_train) # 0.6178724780500952
3-2. 테스트 데이터
pred_test=model.predict(X_scaled_test)
model.score(X_scaled_test, y_test) # 0.5974112241813845
① RMSE (Root Mean Squared Error)
import numpy as np
from sklearn.metrics import mean_squared_error
MSE_train = mean_squared_error(y_train, pred_train)
MSE_test = mean_squared_error(y_test, pred_test)
print("훈련 데이터 RMSE:", np.sqrt(MSE_train))
print("테스트 데이터 RMSE:", np.sqrt(MSE_test))