데이터 분석/실습
US Election 2020
eunki
2021. 12. 27. 19:03
728x90
US Election 2020
Race to Presidential Election 2020 by County
www.kaggle.com
https://www.kaggle.com/muonneutrino/us-census-demographic-data
US Census Demographic Data
Demographic and Economic Data for Tracts and Counties
www.kaggle.com
데이터 정보
- president_county_candidate.csv: 대통령 투표 결과
- governors_county_candidate.csv: 카운티 지사 투표 결과
- acs2017_county_data.csv: 카운티별 인구조사 데이터
- state: 주
- county: 카운티(군)
- district: 지구
- candidate: 후보자
- party: 후보자의 소속 정당
- total_votes: 득표 수
- won: 지역 투표 우승 여부
데이터셋 준비
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns# from US Election 2020
df_pres = pd.read_csv('../input/us-election-2020/president_county_candidate.csv')
df_gov = pd.read_csv('../input/us-election-2020/governors_county_candidate.csv')
# from US Census 2017
df_census = pd.read_csv('../input/us-census-demographic-data/acs2017_county_data.csv')EDA 및 데이터 기초 통계 분석
df_pres.head()
df_pres['candidate'].unique()array(['Joe Biden', 'Donald Trump', 'Jo Jorgensen', 'Howie Hawkins',
' Write-ins', 'Gloria La Riva', 'Brock Pierce',
'Rocky De La Fuente', 'Don Blankenship', 'Kanye West',
'Brian Carroll', 'Ricki Sue King', 'Jade Simmons',
'President Boddie', 'Bill Hammons', 'Tom Hoefling',
'Alyson Kennedy', 'Jerome Segal', 'Phil Collins',
' None of these candidates', 'Sheila Samm Tittle', 'Dario Hunter',
'Joe McHugh', 'Christopher LaFontaine', 'Keith McCormic',
'Brooke Paige', 'Gary Swing', 'Richard Duncan', 'Blake Huber',
'Kyle Kopitke', 'Zachary Scalf', 'Jesse Ventura', 'Connie Gammon',
'John Richard Myers', 'Mark Charles', 'Princess Jacob-Fambro',
'Joseph Kishore', 'Jordan Scott'], dtype=object)
df_pres.loc[df_pres['candidate'] == 'Joe Biden']['total_votes'].sum() # 82046434유력 대선후보인 Joe Biden의 총 투표수는 82046434표이다.
df_pres.loc[df_pres['candidate'] == 'Donald Trump']['total_votes'].sum() # 74585705유력 대선후보인 Donald Trump의 총 투표수는 74585705표이다.
df_gov.head()
df_census.head()
df_census['County'].value_counts()Washington County 30
Jefferson County 25
Franklin County 24
Jackson County 23
Lincoln County 23
..
Nantucket County 1
Hampden County 1
Dukes County 1
Berkshire County 1
Yauco Municipio 1
Name: County, Length: 1955, dtype: int64
# County별 통계로 데이터프레임 구조 변경
# 모든 데이터프레임의 index를 County로 변경
# 민주당(DEM)과 공화당(REP)에 해당하는 데이터만 사용
data = df_pres.loc[df_pres['party'].apply(lambda s: str(s) in ['DEM', 'REP'])]
table_pres = pd.pivot_table(data=data, index=['state', 'county'], columns='party', values='total_votes')
table_pres.rename({'DEM':'Pres_DEM', 'REP':'Pres_REP'}, axis=1, inplace=True)
table_pres
data = df_gov.loc[df_gov['party'].apply(lambda s: str(s) in ['DEM', 'REP'])]
table_gov = pd.pivot_table(data=data, index=['state', 'county'], columns='party', values='votes')
table_gov.rename({'DEM':'Gov_DEM', 'REP':'Gov_REP'}, axis=1, inplace=True)
table_gov
df_census.rename({'State':'state', 'County':'county'}, axis=1, inplace=True)
df_census.drop(['CountyId', 'Income', 'IncomeErr', 'IncomePerCapErr'], axis=1, inplace=True)
df_census.set_index(['state', 'county'], inplace=True)
df_census
# 다중공선성을 피하기 위해 Men, Women 컬럼 데이터를 남성 비율로 변경
df_census.drop('Women', axis=1, inplace=True)
df_census['Men'] /= df_census['TotalPop']
df_census['VotingAgeCitizen'] /= df_census['TotalPop']
df_census['Employed'] /= df_census['TotalPop']df_census.head()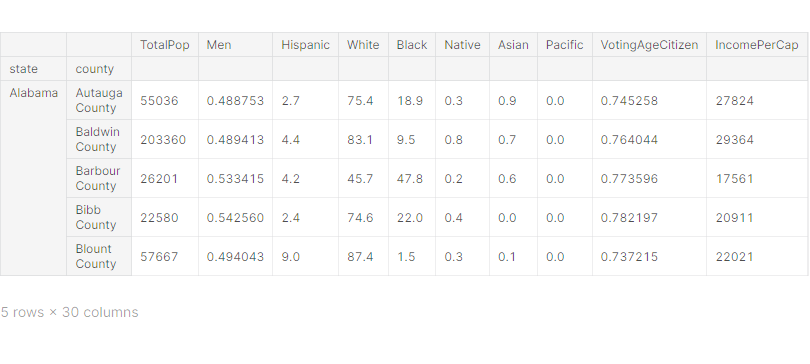
# df_pres, df_gov, df_census 데이터프레임 하나로 결합
df = pd.concat([table_pres, table_gov, df_census], axis=1)
df
# seaborn의 heatmap()로 히트맵 그리기
fig = plt.figure(figsize=(12, 12))
sns.heatmap(df.corr())
fig = plt.figure(figsize=(5, 12))
sns.heatmap(df.corr()[['Pres_DEM', 'Pres_REP']], annot=True)
대통령 선거에서 민주당과 공화당의 연관성이 매우 높게 나타난다. → 데이터 처리 필요
df_norm = df.copy()# 데이터 정규화(normalize)
df_norm['Pres_DEM'] /= df['Pres_DEM'] + df['Pres_REP']
df_norm['Pres_REP'] /= df['Pres_DEM'] + df['Pres_REP']
df_norm['Gov_DEM'] /= df['Gov_DEM'] + df['Gov_REP']
df_norm['Gov_REP'] /= df['Gov_DEM'] + df['Gov_REP']
# 정규화된 데이터로 다시 correlation 확인
fig = plt.figure(figsize=(12, 12))
sns.heatmap(df_norm.corr())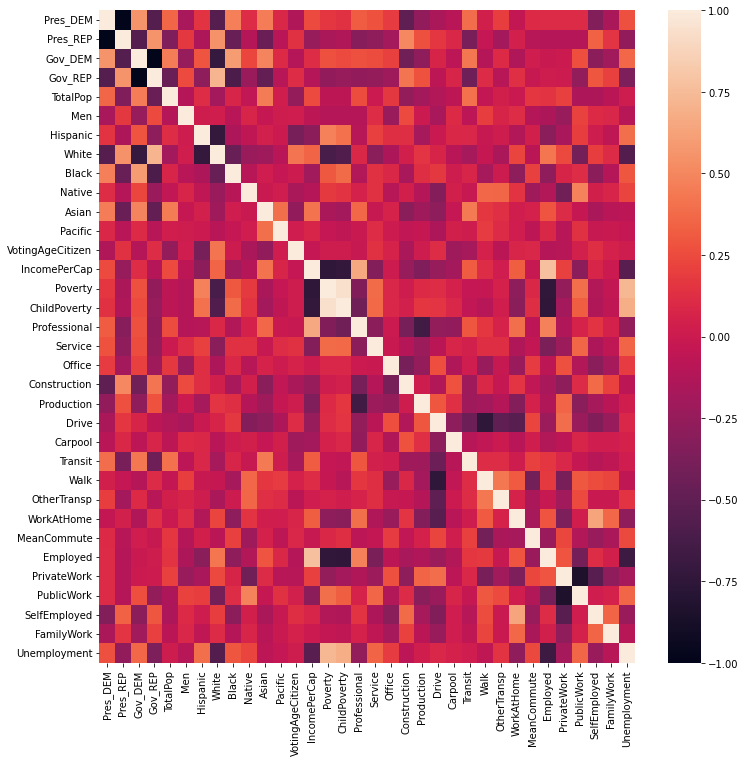
fig = plt.figure(figsize=(5, 12))
sns.heatmap(df_norm.corr()[['Pres_DEM', 'Pres_REP']], annot=True)
대통령 선거에서 흑인과 아시아인의 민주당 투표율이 높다.
대통령 선거에서 백인과 건설직의 공화당 투표율이 높다.
# seaborn의 jointplot()로 산점도와 히스토그램을 함께 그리기
sns.jointplot(x='White', y='Pres_REP', data=df_norm, alpha=0.2)
백인은 대통령 선거에서 공화당을 선택했을 가능성이 높다.
sns.jointplot(x='Black', y='Pres_DEM', data=df_norm, alpha=0.2)
흑인은 대통령 선거에서 민주당을 선택했을 가능성이 높지만, 흑인이 아니어도 민주당을 선택한 사람들이 많다.
데이터 전처리
from sklearn.preprocessing import StandardScaler
# 투표 결과에 해당하는 데이터는 입력 데이터에서 제거
# 예측 타겟은 DEM vs. REP 투표 비율로 함
df_norm.dropna(inplace=True)
X = df_norm.drop(['Pres_DEM', 'Pres_REP', 'Gov_DEM', 'Gov_REP'], axis=1)
y = df_norm['Pres_DEM']
# StandardScaler을 이용하여 수치형 데이터 표준화 진행
scaler = StandardScaler()
scaler.fit(X)
X_scaled = scaler.transform(X)
X = pd.DataFrame(X_scaled, index=X.index, columns=X.columns)X.head()
학습 데이터와 테스트 데이터 분리
from sklearn.model_selection import train_test_split
# train_test_split을 이용하여 학습 데이터와 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)PCA를 이용한 차원 축소
from sklearn.decomposition import PCA
# PCA를 이용하여 Dimensionality Reduction 수행
# n_components를 설정하지 않으면 차원축소를 하지 않고 PCA 진행
# Variance를 잘 설명하는 컬럼이 앞쪽에 배치됨 → 중요도 순서
pca = PCA()
pca.fit(X_train)
plt.plot(range(1, len(pca.explained_variance_) + 1), pca.explained_variance_)
plt.grid()
Dimensionality를 10개 사용해도 대부분의 Variance가 표현 가능하다.
# n_components 옵션으로 컬럼을 n개로 축소
pca = PCA(n_components=10)
pca.fit(X_train)
Regression 모델 학습
1. LightGBM Regression 모델
from lightgbm import LGBMRegressor# LGBMRegressor 모델 생성/학습
model_reg = LGBMRegressor()
# model_reg.fit(pca.transform(X_train), y_train)
model_reg.fit(X_train, y_train)피쳐에 PCA를 적용하지 않았을 때 정확도가 더 높았다.
from sklearn.metrics import mean_absolute_error, mean_squared_error
from sklearn.metrics import classification_report
from math import sqrt# mean_absolute_error, rmse, classification_report 결과 출력
# 타겟 변수가 수치형 데이터이기 때문에, 투표율이 50%를 넘었을 때를 기준으로 함
# pred = model_reg.predict(pca.transform(X_test))
pred = model_reg.predict(X_test)
print(mean_absolute_error(y_test, pred))
print(sqrt(mean_squared_error(y_test, pred)))
print(classification_report(y_test > 0.5, pred > 0.5))0.053261679672733014
0.07527410114651
precision recall f1-score support
False 0.97 0.98 0.97 146
True 0.80 0.71 0.75 17
accuracy 0.95 163
macro avg 0.88 0.84 0.86 163
weighted avg 0.95 0.95 0.95 163
MAE = 0.053261679672733014
RMSE = 0.07527410114651
정확도(accuracy) = 0.95 (95%)
Classification 모델 학습
1. XGBoost 모델
from xgboost import XGBClassifier# XGBClassifier 모델 생성/학습
model_cls = XGBClassifier(use_label_encoder=False, eval_metric='mlogloss')
model_cls.fit(X_train, y_train > 0.5)
pred = model_cls.predict(X_test)
print(classification_report(y_test > 0.5, pred)) precision recall f1-score support
False 0.96 0.97 0.97 146
True 0.73 0.65 0.69 17
accuracy 0.94 163
macro avg 0.85 0.81 0.83 163
weighted avg 0.94 0.94 0.94 163
정확도(accuracy) = 0.94 (94%)
모델 학습 결과 심화 분석
1. XGBoost 모델로 특징의 중요도 확인
# XGBoost 모델의 feature_importances_ 속성으로 plot 그리기
plt.bar(X.columns, model_cls.feature_importances_)
plt.xticks(rotation=90)
plt.show()
TotalPop 피쳐 중요도가 가장 높다.
728x90