Students' Academic Performance
https://www.kaggle.com/aljarah/xAPI-Edu-Data
Students' Academic Performance Dataset
xAPI-Educational Mining Dataset
www.kaggle.com
데이터 정보
- gender: 학생의 성별 (M: 남성, F: 여성)
- NationaliTy: 학생의 국적
- PlaceofBirth: 학생이 태어난 국가
- StageID: 학생이 다니는 학교 (초,중,고)
- GradeID: 학생이 속한 성적 등급
- SectionID: 학생이 속한 반 이름
- Topic: 수강한 과목
- Semester: 수강한 학기 (1학기/2학기)
- Relation: 주 보호자와 학생의 관계
- raisedhands: 학생이 수업 중 손을 든 횟수
- VisITedResources: 학생이 교과 과정을 방문한 횟수
- AnnouncementsView: 학생이 과목 공지를 확인한 횟수
- Discussion: 학생이 토론 그룹에 참여한 횟수
- ParentAnsweringSurvey: 부모가 학교 설문에 참여했는지 여부
- ParentschoolSatisfaction: 부모가 학교에 만족했는지 여부
- StudentAbscenceDays: 학생의 결석 횟수 (7회 이상/미만)
- Class: 학생의 성적 등급 (L: 낮음, M: 보통, H: 높음)
데이터셋 준비
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns# pd.read_csv()로 csv파일 읽어들이기
df = pd.read_csv('../input/xAPI-Edu-Data/xAPI-Edu-Data.csv')EDA 및 데이터 기초 통계 분석
df.head()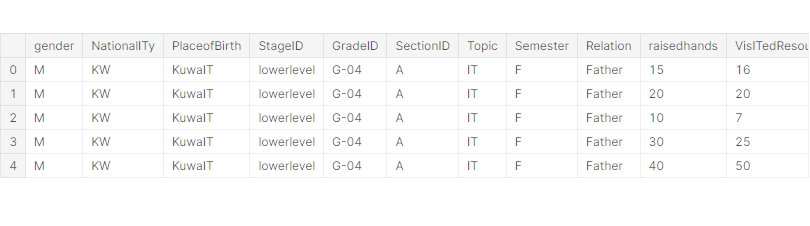
수치형 데이터: raisedhands, VisITedResources, AnnouncementsView, Discussion
범주형 데이터: gender, NationalITy, PlaceofBirth, StageID, GradeID, SectionID, Topic, Semester, Relation, ParentAnsweringSurvey, ParentschoolSatisfaction, StudentAbsenceDays
타겟 데이터: Class
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 480 entries, 0 to 479
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 gender 480 non-null object
1 NationalITy 480 non-null object
2 PlaceofBirth 480 non-null object
3 StageID 480 non-null object
4 GradeID 480 non-null object
5 SectionID 480 non-null object
6 Topic 480 non-null object
7 Semester 480 non-null object
8 Relation 480 non-null object
9 raisedhands 480 non-null int64
10 VisITedResources 480 non-null int64
11 AnnouncementsView 480 non-null int64
12 Discussion 480 non-null int64
13 ParentAnsweringSurvey 480 non-null object
14 ParentschoolSatisfaction 480 non-null object
15 StudentAbsenceDays 480 non-null object
16 Class 480 non-null object
dtypes: int64(4), object(13)
memory usage: 63.9+ KB(480, 17) → 480 rows 17 columns
null 데이터 없음
df.describe()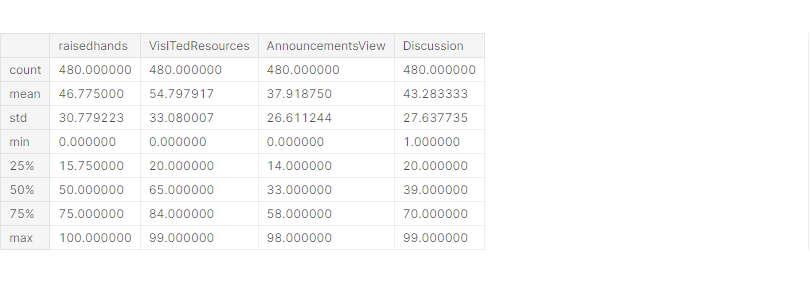
df['gender'].value_counts()M 305
F 175
Name: gender, dtype: int64여학생보다 남학생의 수가 더 많다.
df['NationalITy'].value_counts()KW 179
Jordan 172
Palestine 28
Iraq 22
lebanon 17
Tunis 12
SaudiArabia 11
Egypt 9
Syria 7
USA 6
Iran 6
Lybia 6
Morocco 4
venzuela 1
Name: NationalITy, dtype: int64대부분 쿠웨이트와 요르단 국적의 학생들이다.
df['PlaceofBirth'].value_counts()KuwaIT 180
Jordan 176
Iraq 22
lebanon 19
SaudiArabia 16
USA 16
Palestine 10
Egypt 9
Tunis 9
Iran 6
Syria 6
Lybia 6
Morocco 4
venzuela 1
Name: PlaceofBirth, dtype: int64
# seaborn의 histplot()로 히스토그램 그리기
# hue_order 옵션으로 hue 순서 결정
sns.histplot(x='raisedhands', data=df, hue='Class', hue_order=['L', 'M', 'H'], kde=True)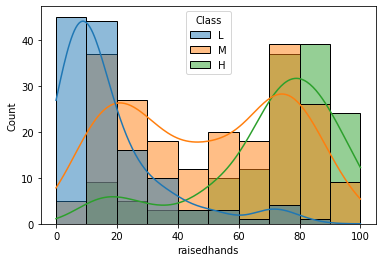
학생이 수업 중 손을 든 횟수(raisedhands)가 많을수록 성적 등급이 높게 나온다.
→ 수업 중 손을 든 횟수는 성적 등급에 영향을 준다.
sns.histplot(x='VisITedResources', data=df, hue='Class', hue_order=['L', 'M', 'H'], kde=True)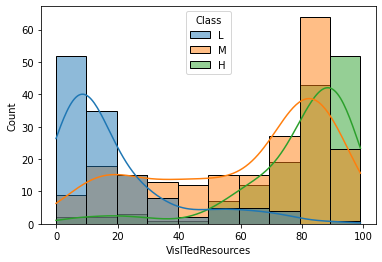
학생이 교과 과정을 방문한 횟수(VisITedResources)가 많을수록 성적 등급이 높게 나온다.
M, H 성적 등급의 대부분 학생들은 교과 과정 방문 횟수가 많다.
→ 교과 과정을 방문한 횟수는 성적 등급에 영향을 준다.
sns.histplot(x='AnnouncementsView', data=df, hue='Class', hue_order=['L', 'M', 'H'], kde=True)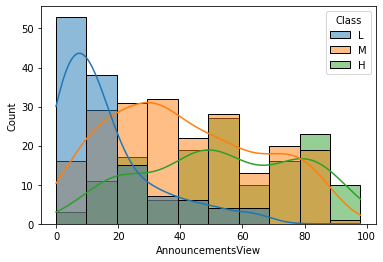
L 성적 등급의 학생들은 과목 공지를 확인한 횟수가 적다.
M, H 성적 등급의 학생들이 과목 공지를 확인한 횟수의 분산이 크다.
→ 과목 공지를 확인한 횟수(AnnouncementsView)는 성적 등급에 영향을 주는지 확실히 알 수 없다.
sns.histplot(x='Discussion', data=df, hue='Class', hue_order=['L', 'M', 'H'], kde=True)
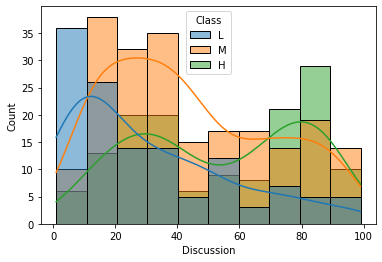
학생이 토론 그룹에 참여한 횟수(Discussion)는 성적 등급에 영향을 주지 않는 것으로 보인다.
# seaborn의 jointplot()로 산점도와 히스토그램을 함께 그리기
sns.jointplot(x='VisITedResources', y='raisedhands', data=df, hue='Class', hue_order=['L', 'M', 'H'])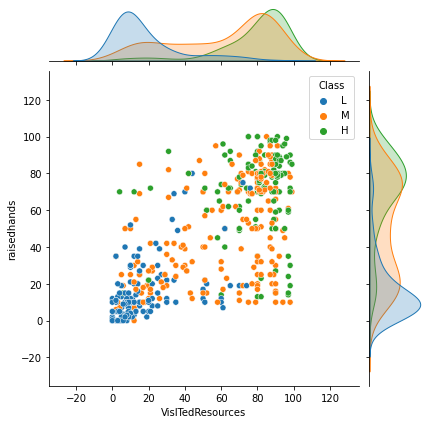
학생이 교과 과정을 방문한 횟수(VisITedResources)와 학생이 수업 중 손을 든 횟수(raisedhands)가 많을수록 성적 등급이 높다.
# seaborn의 pairplot()로 모든 경우의 jointplot을 한 번에 그리기
sns.pairplot(df, hue='Class', hue_order=['L', 'M', 'H'])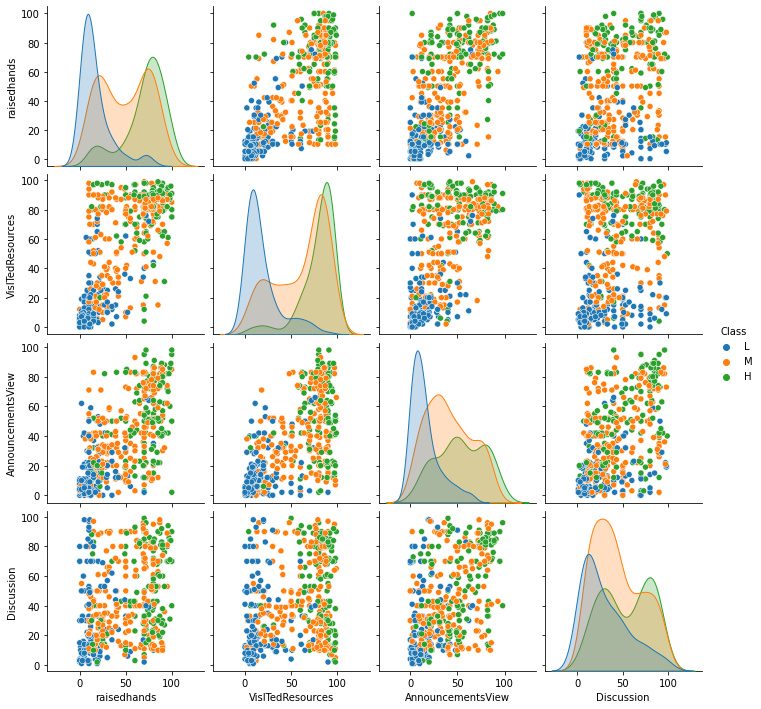
결과가 y=x 형태로 나타날수록 두 변수의 상관성이 높다.
feature간의 correlation이 낮을수록 분석하기 좋다.
# seaborn의 countplot()로 범주별 통계 그리기
sns.countplot(x='Class', data=df, order=['L', 'M', 'H'])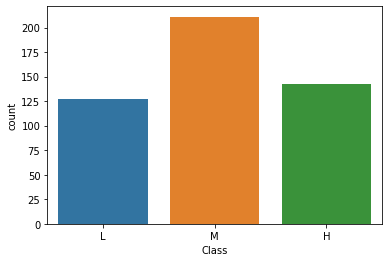
성적 등급이 M(보통)인 학생들이 가장 많다.
sns.countplot(x='gender', data=df, hue='Class', hue_order=['L', 'M', 'H'])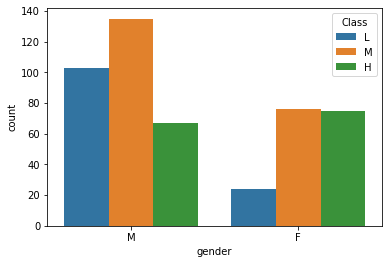
남학생들은 대부분 성적 등급이 M, L인 반면에 여학생들은 M, H 이다.
→ 대체로 여학생이 남학생보다 성적 등급이 높다.
sns.countplot(x='NationalITy', data=df, hue='Class', hue_order=['L', 'M', 'H'])
plt.xticks(rotation=90)
plt.show()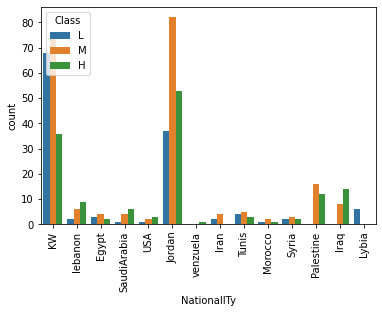
대체로 쿠웨이트 국적의 학생보다 요르단 국적의 학생의 성적 등급이 더 높다.
베네수엘라 국적의 학생들은 모두 H 등급이고 리비아 국적의 학생들은 모두 L 등급이지만,
학생 수가 적기 때문에 상관관계를 확신할 수 없다.
sns.countplot(x='ParentAnsweringSurvey', data=df, hue='Class', hue_order=['L', 'M', 'H'])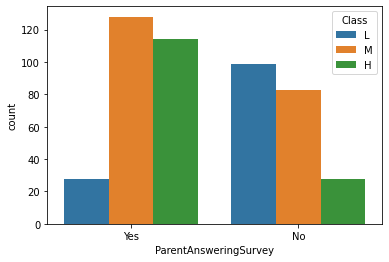
부모가 학교 설문에 참여한 학생이 그렇지 않은 학생보다 성적 등급이 더 높다.
sns.countplot(x='ParentschoolSatisfaction', data=df, hue='Class', hue_order=['L', 'M', 'H'])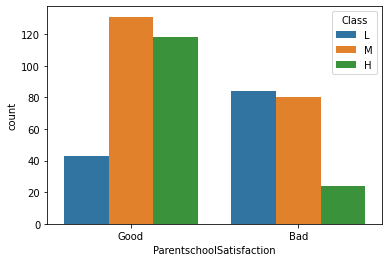
부모가 학교에 만족한 학생이 그렇지 않은 학생보다 성적 등급이 더 높다.
하지만 자녀의 성적이 좋기 때문에 부모가 학교에 만족한 것일 수도 있다.
설문 조사가 진행된 시기가 성적이 나오기 전/후인지 알 수 없기 때문에 분석에서 제외하는 것이 좋다.
sns.countplot(x='Topic', data=df, hue='Class', hue_order=['L', 'M', 'H'])
plt.xticks(rotation=90)
plt.show()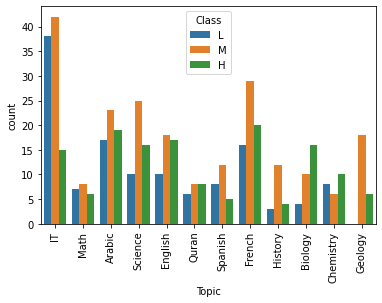
IT 과목에서 높은 성적 등급을 받기 어려운 것으로 보인다.
생물학 과목을 수강한 학생들의 성적 등급은 높은 편이다.
# 범주형 데이터인 타겟 컬럼을 수치로 바꾸어 표현
# L: -1, M: 0, H:1
df['Class_value'] = df['Class'].map({'L': -1, 'M': 0, 'H': 1})
df.head()
gb = df.groupby('gender').mean()['Class_value']
plt.bar(gb.index, gb)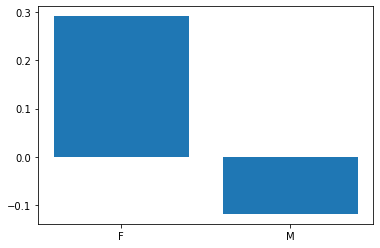
여학생이 남학생보다 평균 성적 등급이 높다.
# ascending=True : 오름차순 정렬
gb = df.groupby('Topic').mean()['Class_value'].sort_values()
plt.barh(gb.index, gb)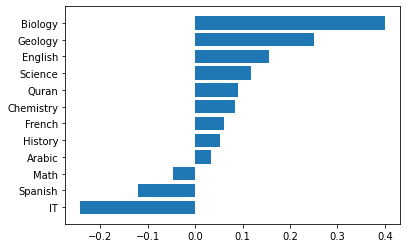
IT, 스페인어, 수학을 수강한 학생들의 평균 성적 등급은 낮은 편이다.
생물학, 지질학, 영어를 수강한 학생들의 평균 성적 등급은 높은 편이다.
# ascending=False : 내림차순 정렬
gb = df.groupby('StudentAbsenceDays').mean()['Class_value'].sort_values(ascending=False)
plt.bar(gb.index, gb)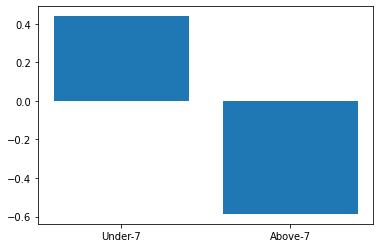
결석 횟수가 7회를 넘지 않는 학생이 넘는 학생보다 평균 성적 등급이 높다.
데이터 전처리
# get_dummies()를 이용하여 범주형 데이터 전처리
# drop_first 옵션으로 첫 번째 카테고리 값 사용 결정
X = pd.get_dummies(df.drop(['ParentschoolSatisfaction', 'Class', 'Class_value'], axis=1),
columns=['gender', 'NationalITy', 'PlaceofBirth',
'StageID', 'GradeID', 'SectionID', 'Topic',
'Semester', 'Relation', 'ParentAnsweringSurvey',
'StudentAbsenceDays'],
drop_first=True)
y = df['Class']X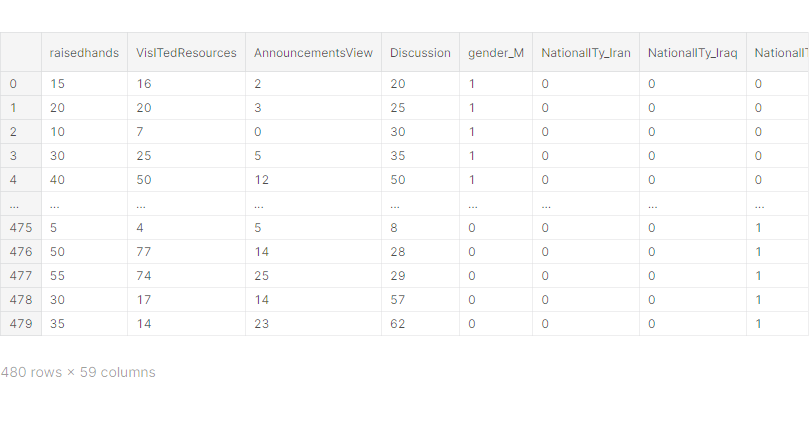
학습 데이터와 테스트 데이터 분리
from sklearn.model_selection import train_test_split# train_test_split을 이용하여 학습 데이터와 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)Classification 모델 학습
1. Logistic Regression 모델
from sklearn.linear_model import LogisticRegression# LogisticRegression 모델 생성/학습
# STOP: TOTAL NO. of ITERATIONS REACHED LIMIT. -> max_iter 늘리기
model_lr = LogisticRegression(max_iter=10000)
model_lr.fit(X_train, y_train)
from sklearn.metrics import classification_reportpred = model_lr.predict(X_test)
print(classification_report(y_test, pred)) precision recall f1-score support
H 0.77 0.67 0.72 55
L 0.79 0.79 0.79 33
M 0.60 0.68 0.64 56
accuracy 0.70 144
macro avg 0.72 0.71 0.71 144
weighted avg 0.71 0.70 0.70 144
정확도(accuracy) = 0.70 (70%)
2. XGBoost 모델
from xgboost import XGBClassifier# XGBClassifier 모델 생성/학습
model_xgb = XGBClassifier(eval_metric='mlogloss')
model_xgb.fit(X_train, y_train)
pred = model_xgb.predict(X_test)
print(classification_report(y_test, pred)) precision recall f1-score support
H 0.79 0.69 0.74 55
L 0.85 0.85 0.85 33
M 0.65 0.73 0.69 56
accuracy 0.74 144
macro avg 0.76 0.76 0.76 144
weighted avg 0.75 0.74 0.74 144
정확도(accuracy) = 0.74 (74%)
모델 학습 결과 심화 분석
1. Logistic Regression 모델 계수로 상관성 파악
# model_lr.coef_ : rows = target, columns = feature
print(model_lr.coef_.shape) # (3, 59)
print(model_lr.classes_) # ['H' 'L' 'M']# Logistic Regression 모델의 coef_ 속성으로 plot 그리기
# 성적 등급이 'H'인 학생들의 모든 feature와의 상관관계
fig = plt.figure(figsize=(15, 8))
plt.bar(X.columns, model_lr.coef_[0, :])
plt.xticks(rotation=90)
plt.show()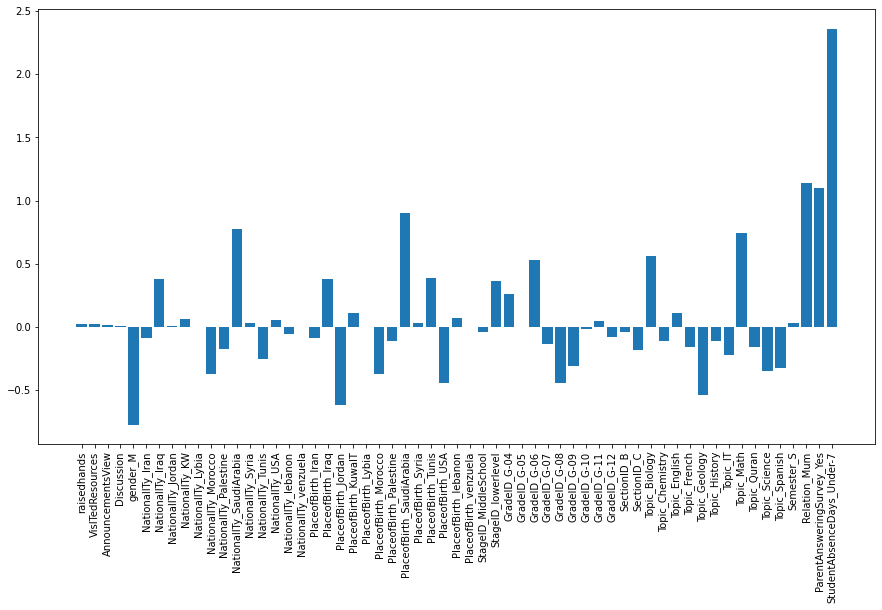
주 보호자가 엄마고, 부모가 학교 설문에 참여했고, 학생의 결석 횟수가 7회 미만일 경우 높은 성적 등급을 받는다.
# 성적 등급이 'L'인 학생들의 모든 feature와의 상관관계
fig = plt.figure(figsize=(15, 8))
plt.bar(X.columns, model_lr.coef_[2, :])
plt.xticks(rotation=90)
plt.show()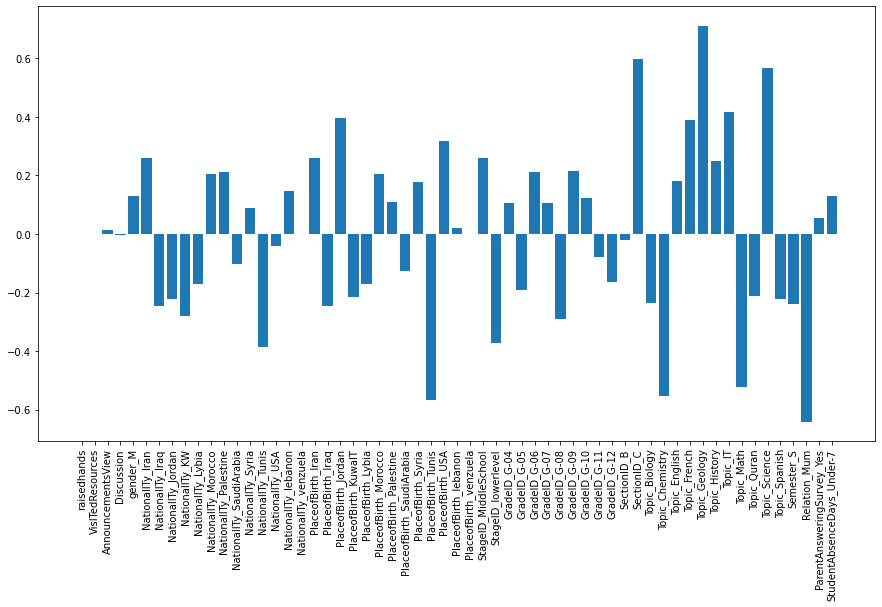
수강 과목이 지질학이나 과학이고, C반에 속해 있는 학생일수록 낮은 성적 등급을 받는다.
2. XGBoost 모델로 특징의 중요도 확인
# XGBoost 모델의 feature_importances_ 속성으로 plot 그리기
# target을 결정하는데 주요하게 사용된 feature
fig = plt.figure(figsize=(15, 8))
plt.bar(X.columns, model_xgb.feature_importances_)
plt.xticks(rotation=90)
plt.show()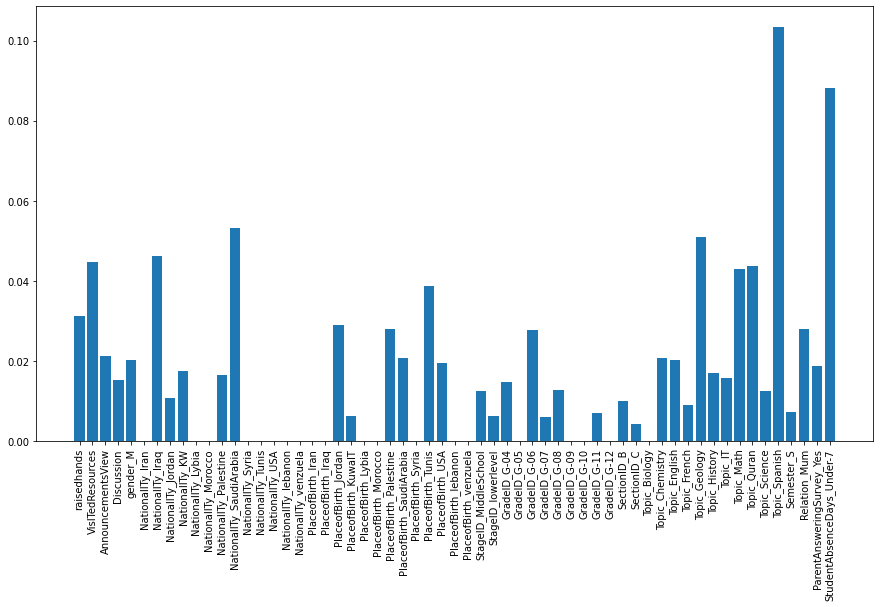
Topic_Spanish와 StudentAbscenceDays_Under-7 피쳐 중요도가 높다.